Pixelated Pictures (source)
Why Did I Make This?
This is a project that I started a very long time ago (in 2006). I was inspired by a puzzle my friend had that was a picture of a Simpsons scene but made up of smaller pictures from The Simpsons. I asked myself, how could one go about doing this? I thought to myself, it might be possible to take an average of each of the RGB values from a picture, then use that average as if it were a single pixel inside a larger picture. I worked on it for a couple of nights and at the end I had something that worked.
I've re-written this project a couple of times since my original attempt. For several reasons. First among them was that this was written while I was teaching at Churchill high school, about two years before I started working towards my Computer Science degree at UTSA. I didn't use very much modularity (basically my methods were huge subroutines), I didn't use any outside libraries (just the Java2 API), and there was no optimizations of any kind. I updated it a few years later to incorporate an external package to handle resizing the images (java-image-scaling-0.8.5). I also attempted to add a threaded approach to processing the picture using the Callable Interface.
I finally re-wrote again this past year (2018), mainly to fix the parallelization issues. Also, being curious if there were already services to do this (there are), I was curious to see what their results were. One of the major improvements in this third attempt was something I noticed from an example I found from a website that does this professionally. I noticed that the individual pictures (inside the larger one), were covering more than just a single pixel. So I updated my database algorithm, to, instead of shrinking a picture into a single pixel, to store it as a 2D array of pixels (like a 3X3 or 2X2).
Technical Description of Project
There are 5 main classes in this project (there are a few others that are more of helper classes, like handling the Callable Interface, handling file traversal, and a name generating class to ensure each resized picture in my database has a unique name):
- PictureDatum.java - This class is used to store the data for each picture in my database of pictures. It holds a reference to the original file, the thumbnail file (compressed and resized), and all of the necessary RGB data from the thumbnail. The RGB data is three 2D arrays for each of the red, green, and blue RGB components (the size is dependent on the chosen subsampling).
- PictureDB.java
- This is an interface which has two primary methods:
find(...)andaddPicture(...). I chose to make this an interface, rather than a concrete class, so that I would have leeway in how it was implemented (i.e. this could be backed by an actual database or XML or just plain text). In testing, I just created a "DummyDB" that used a large text file (not the most efficient but it was quick and easy and this interface allows me to not be tied down to that, if I want to update it in the future). - DBProcessorParallel.java
- This is the class responsible for populating the given
processFiles(final File rootDir, final File dbDir).rootDiris the root folder from where this method will start looking for picture files (and does a full search of all sub-folders).dbDiris the directory where all of the resized thumbnails will go (the pictures that will actually be used for the final image). - PictureResult.java
- This class aids in searching for the best thumbnail match to a
given region of the picture that's being pixelated. It implements
the
Comparable Interfaceso that it can easily be used in a sorted list. Thumbnails are sorted based on the smallest Euclidean distance (squared), when comparing the RGB values, for each region of the thumbnail subsampled. - PixelatePictureBrute.java
- This class scans the image and creates a new image by replacing
regions of the original picture with thumbnails. The
PictureDBdoes most of the heavy lifting for this class since it is responsible for finding the suitable thumbnail. It actually populates a JavaTreeSet, I then randomly choose from the top of this list so that the same picture is not used in similarly colored areas. This still needs to be parallelized.
Process
- First crop the image into a square by either the height or the width (whichever is smaller). Below you can see this picture is cropped based on its height (the white thin bar with black outline represents the crop).

- Then shrink it down to 50x50 pixels (to make for a decent representation) and, finally convert those pixels to a 3x3 array of pixels:
- Those are the pixels I use to find a closest match.
- The pictures I have used are high quality, 4000x6000 pixels, so instead of using a single picture for every pixel (or really, every 3x3 box of pixels), I simply kept the number of pixels and, therefore, essentially scaled the picture down by a factor of ~ 20x20 (50/3 ~ 20). If I do that true to the above picture (which has already been scaled down for loading purposes), you won't see any detail (because I'd be scaling it down to 7x5 pixels).
- Instead, I have scaled down the original pixelation below. You can click the picture to open the full size picture. Give it some time to load because the full picture is 20 MB (because it's a PNG).
Parallelization
This part is somewhat unfinished as I only implemented parallelization in creating the database. The creation of the database is very straightforward to parallelize since the processing of each picture is completely independent. Likewise generating the pixelated picture should be straightforward as well since the task is simply finding the best picture for each subsample--thus is independent.
The idea is simple. Each picture can be analyzed separately so multiple threads should be analyzing different pictures at all times. This presents some challenges though:
- How many threads? (no point in having more threads than the computer can realistically handle)
- How to avoid creation of thousands of threads? Can I reuse resources?
- How to pipe files to the group of threads?
- How does a thread know it should quit (i.e. there won't be anymore files coming)?
The first two are fairly straightforward to handle. I use an Executor to handle the threads in a fixed thread pool based on the Runtime method availableProcessors().
Traversing Files
PictureFileTraversalParallel.java: I used the "poison pill" approach to signal when to stop the processing threads. Essentially each processing thread pops from a queue of files (to be processed). The thread populating the queue, once it has fully traversed the directory, will put a "poison pill" into its queue for each thread. Each processing thread perpetually tries to pop from the queue until it receives the "poison pill" which signals to the processing thread that it can quit and return its result.
The file traversal class uses a LinkedBlockingQueue.
This ensures that, in event the file queue becomes empty, the next
processing thread will wait until the next result comes in. The
method that returns the next file is
synchronized
so that only one processing thread can access the queue at a given
time.
Here are the files responsible for parallization of the database process:
- DBProcessorParallel.java: This class sets up the necessary Callable objects, the PictureFileTraversalParallel object, and places them into proper Executor objects, then runs them.
- PictureFileTraversalParallel.java: This class traverses the directories, finds picture files, and puts them into a queue that can be read by the processing threads.
- DBProcessorParallelCall.java: This is the processing thread. All processing threads share the same PictureFileTraversalParallel object and pop from its internal queue to get the next picture file to be processed.
- NameGen.java: This class is
responsible for generating a unique file name for each generated
thumbnail. This class is necessary because the processing threads
generate the file names for the generated thumbnails. So I need a
synchronizedway of making sure no duplicates are generated. This is a bit of a tradeoff. I could have either created a class that holds the source file name and the thumbnail path and then have the PictureFileTraversalParallel object generate unique names (sequentially), and finally put those objects (that hold the source and thumbnail path) into its queue. Or I could create this NameGen class which specifically handles name generation and push that duty closer to the processing thread (my chosen approach). This way seemed like a cleaner way of doing that. This was unnecessary in the serial case because the single processing thread could simply increment its counter to generate the next file name.
Results
The results were very good for parallelization. In fact they are so good, I realize now that I never actually allowed the serial process to go through my entire set of pictures. As I'm writing this, I'm still waiting on the serial process to finish to give a time comparison:
- The serial test processed 4,066 pictures in 2,064 seconds (34 minutes, 24 seconds).
- The parallel test processed 4,066 files in 540 seconds (9 minutes)--about a 4X speedup.
- That's a "50%" efficiency since I have 8 cores. But most likely I'm seeing a memory bottleneck. I processed ~29.6 GB worth of files (an average of about 7 MB per file--which makes sense because these are mostly from a DSLR camera). In the parallel case that means I'm processing around 55 MB/s vs. about 14 MB/s in the serial case.
- So thinking out loud as I write this, is it a memory bottleneck? So I'm testing to see if it's faster when processing via my M.2 PCIe NVMe SSD hard drive as opposed to my external USB hard drive that the above statistics represent.
- Serial finished in 1,900 seconds (31 minutes, 40 seconds), 15 MB/s, or about 8% faster--not a significant speedup.
- Parallel finished in 395 seconds (6 minutes, 35 seconds), 75 MB/s, or about 37% faster--which is a fairly significant speedup.
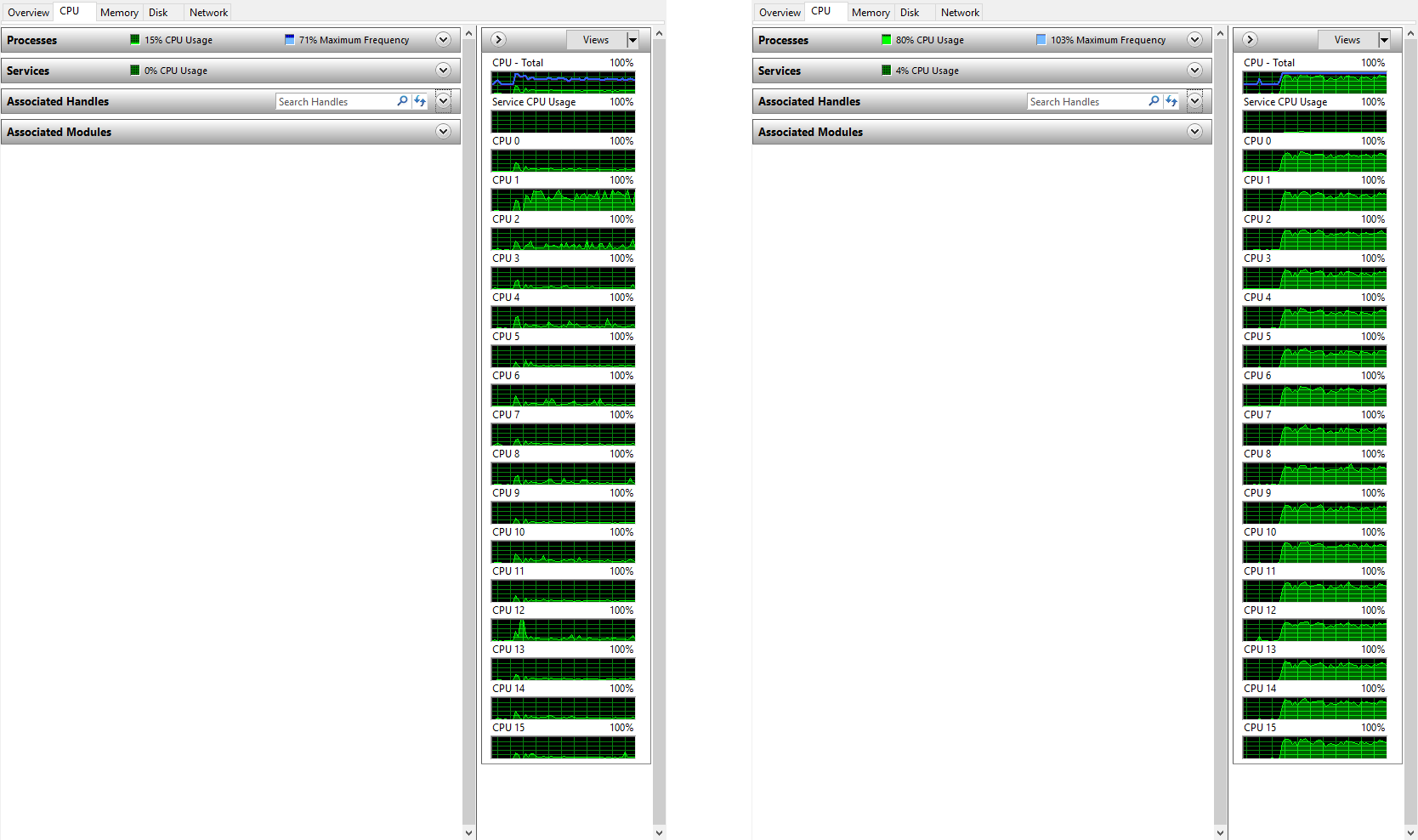
Here is a screenshot comparison of the resource monitor in Windows 10 as each started. I'll leave it up to the reader to decide which one is the parallel vs. serial version.